As traditional libraries have evolved to meet the needs of their patrons, librarians have encountered and addressed a host of metadata-related issues. Today, sophisticated library cataloging principles and schemes help all of us in finding the information that we need in our local library. As work on digital libraries progresses, however, new metadata needs are arising. The increased ease with which a user can now cross the boundaries from one ``library'' to another, the ability to organize online contents into complex structures, and the development of tools that let users transform those structures, all call for a rethinking of what metadata is and how it can be shared.
In the Stanford Digital Library project, we view long-term digital library systems as collections of widely distributed, autonomously maintained services. While searching services are valuable, they are not the only kind of service in the digital library of the future. Remotely usable information processing facilities are also important digital library services. These services provide support for activities such as document summarization, indexing, collaborative annotation, format conversion, bibliography maintenance, and copyright clearance.
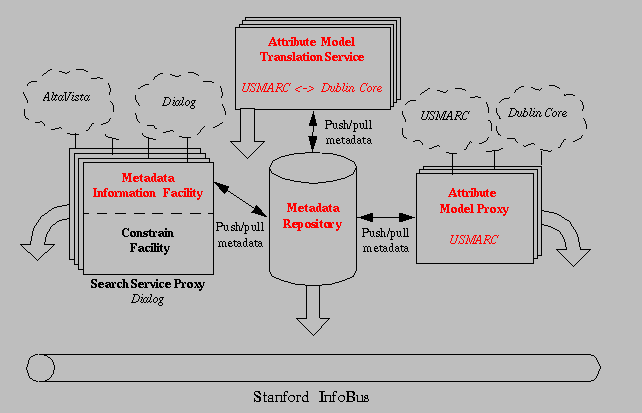
Our project has focused on developing an infrastructure in which these disparate services can communicate and interoperate with one another. Our digital library testbed is providing an infrastructure that affords interoperability among these heterogeneous, autonomous components, much like a hardware bus enables interaction between disparate hardware elements. We call this infrastructure the InfoBus.
In building the InfoBus, we needed to provide services for finding resources likely to satisfy a given query, for formulating queries that are appropriate for multiple sources, for translating queries, and for making sense of query results. These services have been implemented, each with their own metadata processing facilities. But their design has shown that we need a more integrated approach to filling our metadata needs.
In particular, our InfoBus facilities require metadata about the offerings of other services in order to help us decide what services are useful for a particular task. They require protocol-related metadata about those other InfoBus services to determine how to communicate with them. They need metadata about collections of information objects in order to help them decide what collections are relevant for a particular task. Finally, they need metadata about information objects and their underlying representations in order to compare them and to understand their surrounding context.
These needs caused us to design and implement a metadata architecture. We have found that ad hoc approaches to these metadata issues do not scale and cause problems for interoperability. Related work on metadata issues is relevant for specific metadata issues that we have encountered, but does not address the problem of integrating and sharing different types of metadata information in the ways that we require. Accordingly, we have constructed a metadata architecture that is grounded in our digital library experience and builds on current metadata related work. Several pieces of this architecture are implemented; others are under construction.
Our metadata architecture includes the following components:
The current implementation includes six attribute model translators, table-driven query translation, content statistics over the CS-TR collection, and dynamic attribute derivations. We are currently modularizing these facilities, are adding the metadata repository, and are in the process of making our search proxies compliant.